Archives
- Newer posts
- November 2025
- October 2025
- September 2025
- August 2025
- July 2025
- June 2025
- May 2025
- November 2024
- April 2024
- November 2023
- October 2023
- August 2023
- May 2023
- February 2023
- October 2022
- August 2022
- July 2022
- May 2022
- April 2022
- March 2022
- February 2022
- June 2020
- March 2020
- February 2020
- January 2020
- December 2019
- November 2019
- October 2019
- September 2019
- August 2019
- July 2019
- June 2019
- May 2019
- April 2019
- March 2019
- February 2019
- January 2019
- December 2018
- November 2018
- October 2018
- September 2018
- August 2018
- July 2018
- June 2018
- May 2018
- April 2018
- March 2018
- February 2018
- January 2018
- December 2017
- November 2017
- October 2017
- September 2017
- August 2017
- July 2017
- June 2017
- May 2017
- April 2017
- March 2017
- February 2017
- January 2017
- August 2016
- June 2016
- April 2016
- March 2016
- February 2016
- January 2016
- July 2015
- June 2015
- Older posts

Crawling And Scraping With Python
Whenever you have something important that intrigues you, Google is the first place you will go to. And voila, it will show you everything related to what you are searching.
Have you ever wondered how Google provides all the search results matching what you are searching for?
This algorithm is fully dependent on the concept of Crawling and Scraping the web and you will be able to develop your very own crawler and scraper.
What do you mean by Crawling the web?
Crawling is fetching of information from web pages that match the search query provided by the user of the search engine. The collection of web pages is handled by special software bots called crawlers or spiders.
And what about Scraping?
Using the list of webpages that the spider collected, we extract large amounts of data from these pages and store them in a local file or database.
Now let’s get started with developing your very first crawler and scraper.
Requirements:
– Python 3.x (link: https://www.python.org/downloads/) and that’s it, no other software except for a working internet connection.The reason why I am using Python is, this language is easy to learn; even people with no knowledge of programming can dive right into this language. Well this is from my perspective and I have not been paid to advertise on it. For me personally, I love to code in Python, with it’s vast amount of libraries which can even help with machine learning apart from many other things.
Once you have Python properly installed, all you need is a few libraries and you are good to go. (Make sure that ‘python’ and ‘pip’ is added to you system path variables)
To install these libraries, you will have to and type in at the command prompt:
– pip install mechanicalsoup
This will install all the required libraries needed to build your crawler and scraper.
Now at the command prompt, type in python and hit enter.
This opens the python interpreter, which looks something like this:
Next, to import the library required for this project, type in
import mechanicalsoup
Note: The libraries are case sensitive so make sure you type it exactly as above.
Let’s create a browser object, we will call this our spider (as it will crawl the web and fetch the webpages):
browser = mechanicalsoup.StatefulBrowser()
Now, we open a webpage. In this guide we will be using the search engine http://duckduckgo.com, as it is simpler to understand how the pages are crawled and scraped.
browser.open(“http://duckduckgo.com”)
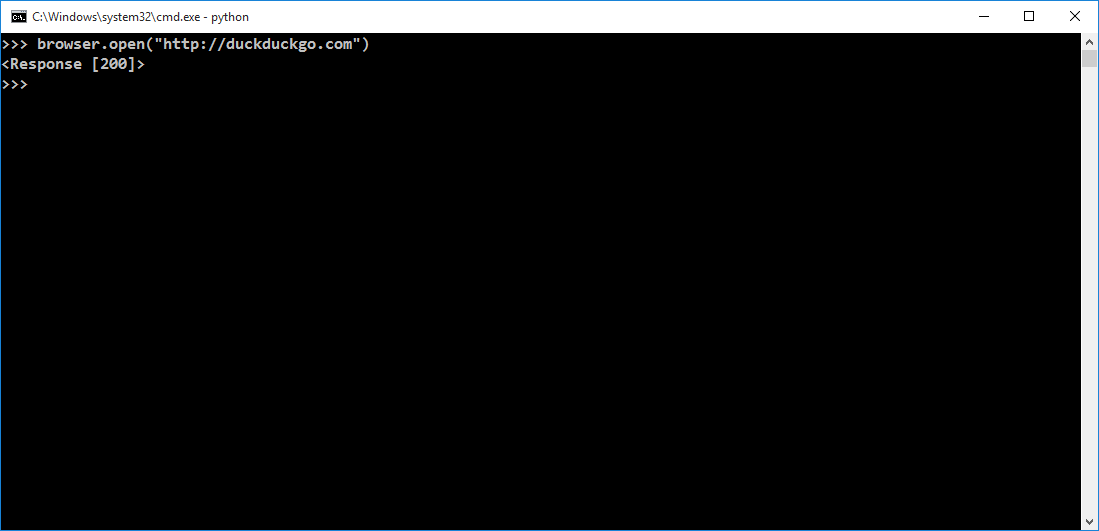
The return value of the method open() is an object of type requests.Response. The output is a HTTP response status, 200, which means “OK”, and the object also contains the contents of the downloaded page which resides within the browser object.
To see the content that exists in the browser object, type in this snippet:
browser.get_current_page()
For the next step, we have to know the attribute that exist for the form tag in the search engine. In our case, we are using the ‘id’ attribute which has the value “#search_form_homepage”. This can be known by using the browser’s Developer tools as shown below:
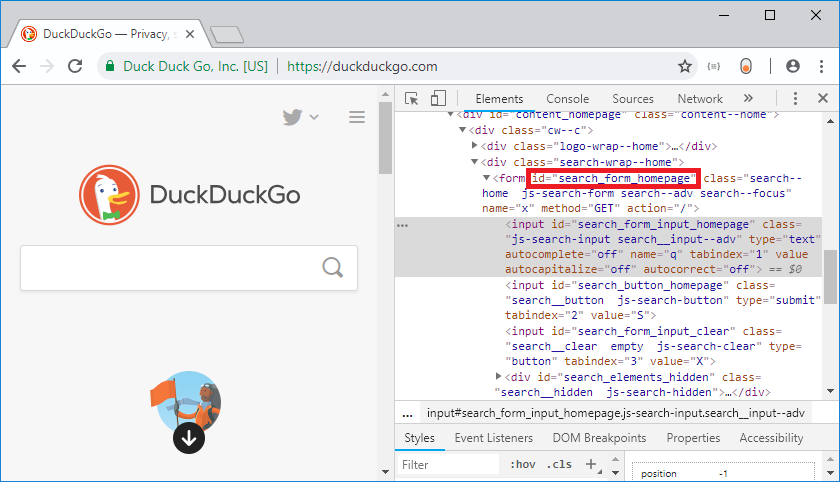
To select this form, type in:
browser.select_form(‘#search_form_homepage’)
To print the summary of the currently selected form, type in:
browser.get_current_form().print_summary()
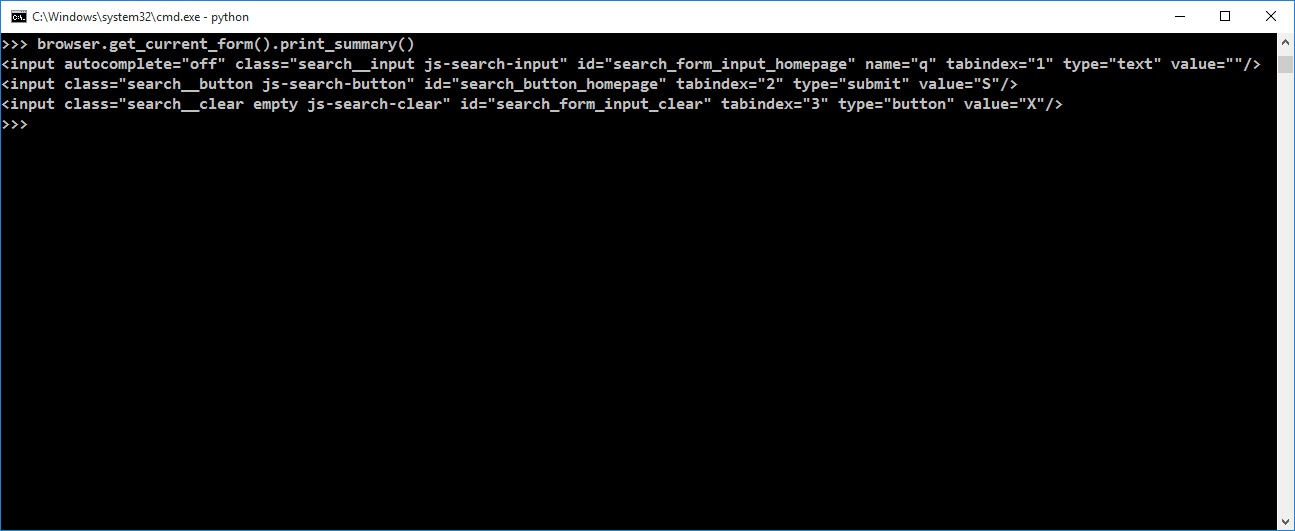
As you can see, there are 3 input tags. From these tags, we will fill the text field which has id “#search_form_input_homepage” with a search query and then submit the selected form.
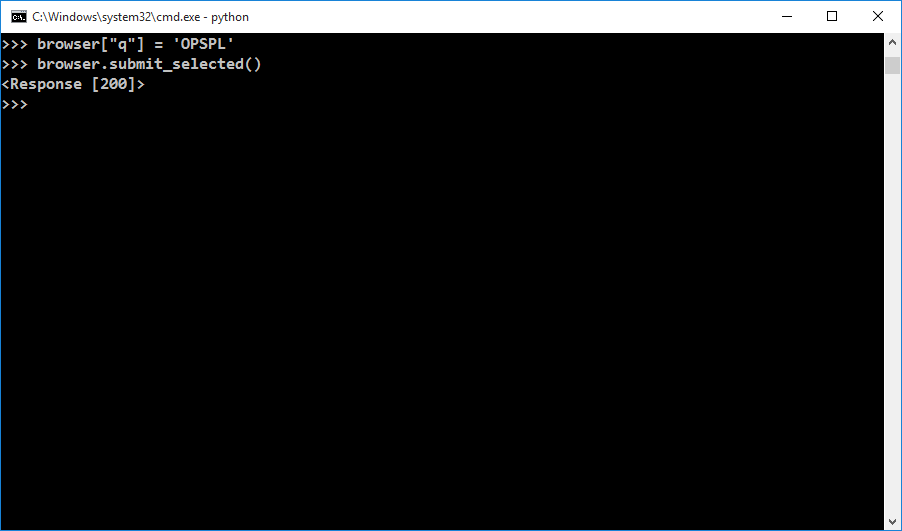
On submitting, you will get status code 200 which states that the request was successful.
Now we need to populate or so to say ‘scrape’ the page for the search results. For now, we only display the results with the title and the link to that search result
Here is the code snippet to display the same:
for link in browser.get_current_page().select(‘a.result__a’):
print(link.text, ‘\n\t’, link.attrs[‘href’])
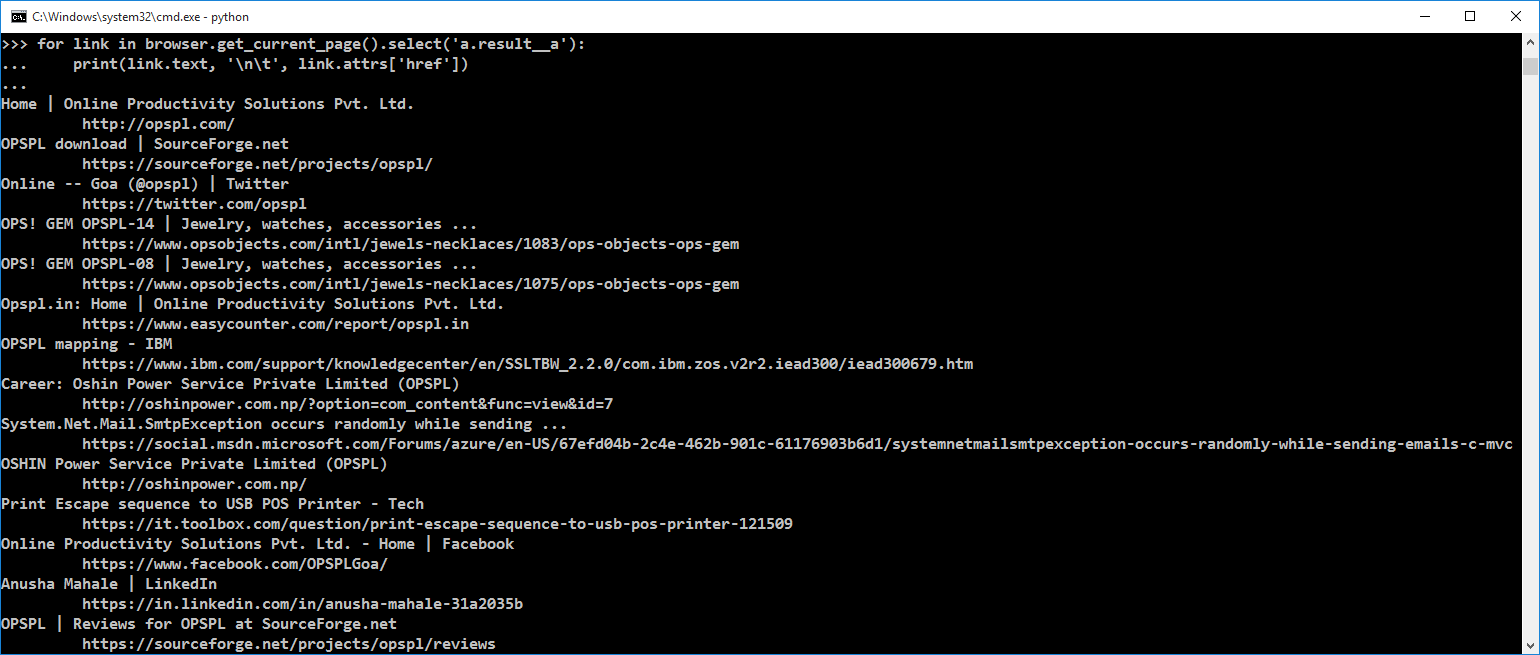
And here comes to an end my guide to creating your own crawler and scraper. You can experiment and explore the documentation of mechanicalsoup (https://mechanicalsoup.readthedocs.io) and beautifulsoup (https://www.crummy.com/software/BeautifulSoup/bs4/doc/) to go even more in-depth into crawling and scraping the web.
